
Научная электронная библиотека
Монографии, изданные в издательстве Российской Академии Естествознания

2.3 ВЫБОР ФУНКЦИИ АКТИВАЦИИ И ОБУЧЕНИЕ НЕЙРОННОЙ СЕТИ
Синапсы осуществляют связь между нейронами и умножают входной сигнал на число, характеризующее силу связи - вес синапса. Сумматор выполняет сложение сигналов, поступающих по синаптическим связям от других нейронов и внешних входных сигналов. Преобразователь реализует функцию одного аргумента, выхода сумматора, в некоторую выходную величину нейрона. Эта функция называется функцией активации нейрона. Нейрон в целом реализует скалярную функцию векторного аргумента. В общем случае входной сигнал и весовые коэффициенты могут принимать действительные значения. Выход определяется видом функции активации и может быть как действительным, так и целым. Синаптические связи с положительными весами называют возбуждающими, с отрицательными весами - тормозящими.
Таким образом, нейрон полностью описывается своими весами и функцией активации F. Получив набор чисел (вектор) в качестве входов, нейрон выдает некоторое число на выходе.
Активационная функция может быть различного вида [61]. Наиболее широко используемые варианты приведены в таблице (табл.2.1).
Одними из наиболее распространенных функций являются:
- 1. линейная,
- 2. нелинейная с насыщением - логистическая функция или сигмоид,
- 3. гиперболический тангенс.
Линейная функция наилучшим образом соответствует сущности данной задачи. Ее областью определения является диапазон (-∞, ∞). Это позволяет, используя ценовые характеристики товара на входе, получать характеристические значения любой величины на выходе, равные их фактической сумме.
Следует отметить, что сигмоидная функция (2.12) дифференцируема на всей оси абсцисс, что широко используется во многих алгоритмах обучения.
Таблица 2.1
Перечень функций активации нейронов
|
Название |
Формула |
Область значений |
|
Пороговая |
|
0, 1 |
|
Знаковая |
|
-1, 1 |
|
Сигмовидная |
|
(0, 1) |
|
Полулинейная |
|
(0, ∞) |
|
Линейная |
|
(-∞, ∞) |
|
Радиальная базисная |
|
(0, 1) |
|
Полулинейная с насыщением |
|
(0, 1) |
|
Линейная с насыщением |
|
(-1, 1) |
|
Гиперболический тангенс |
|
(-1, 1) |
|
Треугольная |
|
(0, 1) |
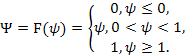
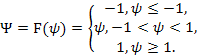
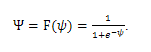 . (2.12)
. (2.12)
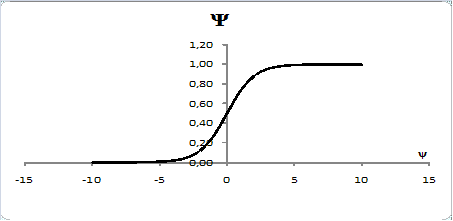
Рис.2.12 Вид сигмоидной функции
Кроме того, она обладает свойством усиливать слабые сигналы лучше, чем сильные, и предотвращает насыщение от сильных сигналов, так как они соответствуют областям аргументов, где сигмоид имеет пологий наклон (рис.2.12). Эти особенности важны для задачи моделирования совершенной конкуренции. Рынок совершенной конкуренции характеризуется однородностью, которая заключается в том, что все производители выпускают одинаковый по числу, свойствам и неценовым характеристикам товар. Единственное отличие однотипных товаров разных производителей - это его ценовые параметры. В условиях рыночной экономики отличия ценовых параметров достаточно характерны для рынков товаров и услуг. Однако они, чаще всего, носят не значительный характер. Поэтому разница между однотипными ценовыми параметрами разных товаров, подаваемых на вход нейронной сети, будет невелика, что предъявляет к чувствительности функции дополнительные требования. Нейроны должны «распознавать» слабо различающиеся входные сигналы. Это делает (2.12) наиболее применимой.
В условиях конкуренции участники рынка, производящие или потребляющие товар по очень высоким или по слишком низким ценам, соответственно, не определяют положение дел на рынке. Основными участниками конкурентной борьбы являются предприятия, действующие в области наиболее конкурентоспособной цены. Это обстоятельство вполне соответствует виду функции (2.12).
Другой широко используемой активационной функцией является гиперболический тангенс. В отличие от логистической функции гиперболический тангенс принимает значения различных знаков, что для ряда сетей оказывается выгодным.
Важно отметить, что выбор вида активационной функции предлагается осуществлять симметрично в производственном и потребительском сегменте по уровням подсистем. Это обосновывается тем, что производство и потребление товара на рынке являются «зеркальными» процессами и должны протекать по одинаковым принципам. Сам же вид функций определяется исходя из требований точности.
При решении с помощью нейронных сетей задач необходимо собрать достаточный и представительный объем данных для того, чтобы обучить нейронную сеть решению таких задач. Обучающий набор данных - это набор наблюдений, содержащих признаки изучаемого объекта. Нейронные сети работают с числовыми данными, взятыми, как правило, из некоторого ограниченного диапазона. В данной задаче эта выборка может быть построена на основе статистической информации, собранной за время существования рынка. Кроме того, количество производителей и поставщиков на рынке совершенной конкуренции достаточно велико и при отсутствии других данных текущие показатели товара могут быть рассмотрены, как обучающая выборка.
Вопрос о том, сколько нужно иметь наблюдений для обучения сети, часто оказывается непростым. Известен ряд эвристических правил, которые устанавливают связь между количеством необходимых наблюдений и размерами сети. Простейшее из них гласит, что количество наблюдений должно быть в 10 раз больше числа связей в сети. На самом деле это число зависит от сложности того отображения, которое должна воспроизводить нейронная сеть. С ростом числа используемых признаков количество наблюдений возрастает по нелинейному закону, так что уже при довольно небольшом числе признаков, скажем 50, может потребоваться огромное число наблюдений. Эта проблема носит название "проклятие размерности".
Таким образом, в условиях первого слоя нейронной системы примерное число обучающих примеров можно определить:
μ = w x l x m. (2.13)
Процесс обучения нейронной сети заключается в определении значений весовых коэффициентов, обеспечивающих однозначное преобразование входных сигналов в выходные.
Путем анализа имеющихся в распоряжении аналитика входных и выходных данных веса сети автоматически настраиваются так, чтобы минимизировать разность между желаемым сигналом и полученным на выходе в результате моделирования. Эта разность носит название ошибки обучения.
Ошибка обучения для конкретной конфигурации нейронной сети определяется путем прогона через сеть всех имеющихся наблюдений и сравнения выходных значений с желаемыми, целевыми значениями. Эти разности позволяют сформировать так называемую функцию ошибок (критерий качества обучения). При моделировании нейронных сетей с линейными функциями активации нейронов можно построить алгоритм, гарантирующий достижение абсолютного минимума ошибки обучения. Для нейронных сетей с нелинейными функциями активации в общем случае нельзя гарантировать достижения глобального минимума функции ошибки.
При таком подходе к процедуре обучения может оказаться полезным геометрический анализ поверхности функции ошибок. Определим веса и смещения как свободные параметры модели и их общее число обозначим через N; каждому набору таких параметров поставим в соответствие одно измерение в виде ошибки сети. Тогда для всевозможных сочетаний весов соответствующую ошибку сети можно изобразить точкой в N-1-мерном пространстве, а все такие точки образуют некоторую поверхность, называемую поверхностью функции ошибок. При таком подходе цель обучения нейронной сети состоит в том, чтобы найти на этой многомерной поверхности глобальный минимум.
В случае линейной модели сети и функции ошибок в виде суммы квадратов такая поверхность будет представлять собой параболоид, который имеет единственный минимум, и это позволяет отыскать такой минимум достаточно просто.
В случае нелинейной модели поверхность ошибок имеет гораздо более сложное строение и обладает рядом неблагоприятных свойств, в частности может иметь локальные минимумы, плоские участки, седловые точки и длинные узкие овраги.
Определить глобальный минимум многомерной функции аналитически невозможно, и поэтому обучение нейронной сети, по сути дела, является процедурой изучения поверхности функции ошибок. Отталкиваясь от случайно выбранной точки на поверхности функции ошибок, алгоритм обучения постепенно отыскивает глобальный минимум. Как правило, для этого вычисляется градиент (наклон) функции ошибок в данной точке, а затем эта информация используется для продвижения вниз по склону. В конце концов алгоритм останавливается в некотором минимуме, который может оказаться лишь локальным минимумом, а если повезет, то и глобальным.
После многократного предъявления примеров веса сети стабилизируются, причем сеть дает правильные ответы на все (или почти все) примеры из базы данных. В таком случае говорят, что «сеть обучена». В программных реализациях можно видеть, что в процессе обучения функция ошибки (например, сумма квадратов ошибок по всем выходам) постепенно уменьшается. Когда функция ошибки достигает нуля или приемлемого малого уровня, тренировку останавливают, а полученную сеть считают натренированной и готовой к применению на новых данных.
Важно отметить, что вся информация, которую сеть имеет о задаче, содержится в наборе примеров. Поэтому качество обучения сети напрямую зависит от количества примеров в обучающей выборке, а также от того, насколько полно эти примеры описывают данную задачу.
Для решения задачи обучения могут быть использованы следующие (итерационные) алгоритмы:
- 1. алгоритмы локальной оптимизации с вычислением частных производных первого порядка;
- 1. алгоритмы локальной оптимизации с вычислением частных производных первого и второго порядка;
- 2. стохастические алгоритмы оптимизации;
- 3. алгоритмы глобальной оптимизации.
К первой группе относятся: градиентный алгоритм (метод скорейшего спуска); методы с одномерной и двумерной оптимизацией целевой функции в направлении антиградиента; метод сопряженных градиентов; методы, учитывающие направление антиградиента на нескольких шагах алгоритма [119, 122].
Ко второй группе относятся: метод Ньютона, методы оптимизации с разреженными матрицами Гессе, квазиньютоновские методы, метод Гаусса-Ньютона, метод Левенберга-Марквардта [128, 131] и другие.
Стохастическими методами являются: поиск в случайном направлении, имитация отжига, метод Монте-Карло (численный метод статистических испытаний).
Задачи глобальной оптимизации решаются с помощью перебора значений переменных, от которых зависит целевая функция (функция ошибки).
При использовании алгоритма обратного распространения ошибки сеть рассчитывает возникающую в выходном слое ошибку и вычисляет вектор градиента как функцию весов. Этот вектор указывает направление кратчайшего спуска по поверхности для данной точки, поэтому если продвинуться в этом направлении, то ошибка уменьшится. Последовательность таких шагов в конце концов приведет к минимуму того или иного типа. Определенную трудность здесь вызывает выбор величины шага.
При большой длине шага сходимость будет более быстрой, но имеется опасность перепрыгнуть через решение или уйти в неправильном направлении. Напротив, при малом шаге, вероятно, будет выбрано верное направление, однако при этом потребуется очень много итераций. На практике величина шага выбирается пропорциональной крутизне склона (градиенту функции ошибок). Такой коэффициент пропорциональности называется параметром скорости настройки. Правильный выбор параметра скорости настройки зависит от конкретной задачи и обычно осуществляется опытным путем. Этот параметр может также зависеть от времени, уменьшаясь по мере выполнения алгоритма.
Алгоритм действует итеративно, и его шаги принято называть эпохами или циклами. На каждом цикле на вход сети последовательно подаются все обучающие наблюдения, выходные значения сравниваются с целевыми значениями, и вычисляется функция ошибки. Значения функции ошибки, а также ее градиента используются для корректировки весов и смещений, после чего все действия повторяются. Начальные значения весов и смещений сети выбираются случайным образом, и процесс обучения прекращается либо когда реализовано определенное количество циклов, либо когда ошибка достигнет некоторого малого значения или перестанет уменьшаться.
Другой подход к процедуре обучения сети можно сформулировать, если рассматривать ее как процедуру, обратную моделированию. В этом случае требуется подобрать такие значения весов, которые обеспечивали бы нужное соответствие между входами и желаемыми значениями на выходе. Такая процедура обучения носит название процедуры адаптации и достаточно широко применяется для настройки параметров нейронных сетей.
Каждый слой производственного сегмента решает свою функциональную задачу в рамках нейронной системы всего рынка. По этой причине процедуру обучения можно выполнять независимо для каждого слоя.
Процесс обучения требует набора примеров ее желаемого поведения - входов H и целевых выходов Ψоpt. Во время этого процесса веса настраиваются так, чтобы минимизировать некоторый функционал ошибки. По умолчанию, в качестве такого функционала для сетей с прямой передачей сигналов принимается среднеквадратичная ошибка между векторами выхода Ψоpt и Ψ.
При обучении сети рассчитывается некоторый функционал, характеризующий качество обучения:
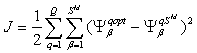 , (2.14)
, (2.14)
где J - функционал; Q - объем выборки; М - число слоев сети; q - номер выборки; Sм - число нейронов выходного слоя; Ψq - вектор сигнала на выходе сети; Ψq opt - вектор желаемых (целевых) значений сигнала на выходе сети для выборки с номером q.
В случае использования линейной активационной функции нейронные сети первого слоя однослойные. В этом случае М = 1 и выражение для функционала принимает вид:
![]() , (2.15)
, (2.15)
где ![]() - функция активации;
- функция активации; ![]() - сигнал на входе функции активации для j-го нейрона;
- сигнал на входе функции активации для j-го нейрона; ![]() - вектор входного сигнала; w - число элементов вектора входа; m - число нейронов в слое;
- вектор входного сигнала; w - число элементов вектора входа; m - число нейронов в слое; ![]() - весовые коэффициенты сети.
- весовые коэффициенты сети.
Включим вектор смещения в состав матрицы весов ![]() , а вектор входа дополним элементом, равным 1.
, а вектор входа дополним элементом, равным 1.
Применяя правило дифференцирования сложной функции, вычислим градиент функционала ошибки, зная при этом, что функция активации дифференцируема:
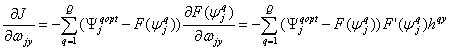 . (2.16)
. (2.16)
Введем обозначение:
![]() . (2.17)
. (2.17)
и преобразуем выражение (2.16) следующим образом:
![]() . (2.18)
. (2.18)
Полученные выражения упрощаются, если сеть линейна. Поскольку для такой сети выполняется соотношение ![]() , то справедливо условие
, то справедливо условие ![]() . В этом случае выражение (2.16) принимает вид:
. В этом случае выражение (2.16) принимает вид:
![]() . (2.19)
. (2.19)
Выражение (2.19) положено в основу алгоритма WH, применяемого для обучения линейных нейронных сетей [132].
Линейные сети могут быть обучены и без использования итерационных методов, а путем решения следующей системы линейных уравнений:
![]() . (2.20)
. (2.20)
Если число неизвестных системы (2.20) равно числу уравнений, то такая система может быть решена, например, методом исключения Гаусса с выбором главного элемента. Если же число уравнений превышает число неизвестных, то решение ищется с использованием метода наименьших квадратов.
В случае нелинейной функции активации для обучения нейронных сетей предлагается применить метод обратного распространения ошибки.
Алгоритм обратного распространения ошибки является одним из эффективных обучающих алгоритмов [130]. По существу он представляет собой минимизационный метод градиентного спуска. Рассмотрим алгоритм обратного распространения ошибки для нейронной сети с одним скрытым слоем. Предположим, что имеется A исходных примеров:
![]() = , (2.21)
= , (2.21)
где ![]() - вектор желаемых выходов сети, соответствующий входному вектору
- вектор желаемых выходов сети, соответствующий входному вектору ![]() .
.
Инициализируем вектор весов Ω случайным образом.
Теперь нужно осуществить настройку весов сети с помощью процесса обучения. Для a-го примера выходы скрытых нейронов будут определяться выражениями:
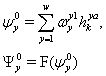 , (2.22)
, (2.22)
а выходы всей нейросети - выражениями:
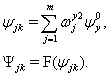 (2.23)
(2.23)
В выражениях (2.22) и (2.23), F() - функция активации, например, сигмоидная функция.
Функционал квадратичной ошибки сети для данного входного образа имеет вид:
![]() (2.24)
(2.24)
Данный функционал подлежит минимизации. Классический градиентный метод оптимизации состоит в итерационном уточнении аргумента согласно формуле:
![]() , (2.25)
, (2.25)
где h - коэффициент скорости обучения 0<η<1.
Параметр η имеет смысл темпа обучения и выбирается достаточно малым для сходимости метода.
Функция ошибки в явном виде не содержит зависимости от веса ![]() , поэтому воспользуемся формулами неявного дифференцирования сложной функции:
, поэтому воспользуемся формулами неявного дифференцирования сложной функции:
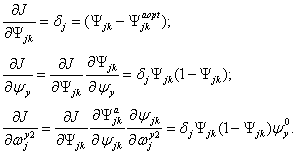 (2.26)
(2.26)
Производная сигмоидной функции выражается только через само значение функции. Таким образом, все необходимые величины для подстройки весов выходного слоя получены.
Выполняется подстройка весов скрытого слоя:
![]() (2.27)
(2.27)
Вычисляются производные функции ошибки:
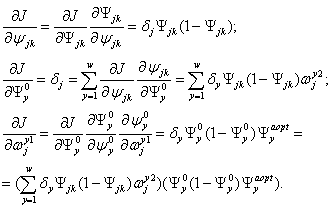 (2.26)
(2.26)
При вычислении d здесь и был применен принцип обратного распространения ошибки: частные производные берутся только по переменным последующего слоя. По полученным формулам модифицируются веса нейронов скрытого слоя.
Вычисления (2.22)-(2.26) повторяются для всех обучающих векторов. Обучение завершается по достижении малой полной ошибки или максимально допустимого числа итераций.
Сходимость метода обратного распространения весьма медленная. Невысокий темп сходимости является особенностью всех градиентных методов, так как локальное направление градиента отнюдь не совпадает с направлением к минимуму. Подстройка весов выполняется независимо для каждой пары образов обучающей выборки. При этом улучшение функционирования на некоторой заданной паре может приводить к ухудшению работы на предыдущих образах.
Несмотря на то, что алгоритм обратного распространения ошибки достаточно прост, он требует обычно тысячи итераций для обучения нейросети. Если требований к точности нет, то следует использовать первый способ (2.14)-(2.20).
Для определения весов входов нейронов второго слоя, а также третьего слоя производственного сегмента нейронной системы обучение не требуется. Значения весов, в силу равнозначности положения всех производителей на рынке, выбираются равными. Никто из них не занимает по условию совершенной конкуренции привилегированного положения. Эти же принципы применимы и к товарам.
По аналогии определяются веса нейронной подсистемы потребительского сегмента рынка.
Главным этапом применения предложенной нейронной системы является процесс ее непосредственной эксплуатации. Цель этого этапа заключается в решении основной задачи - определении характеристик товара, обеспечивающих его производителю конкурентные преимущества и удовлетворяющего запросы потребителей.