
Научная электронная библиотека
Монографии, изданные в издательстве Российской Академии Естествознания

2.6. Правило принятия решения при нормальной плотности вероятностей признаков
В соответствии с выражением (2.4.1) структура байесовского алгоритма принятия решения определяется в основном видом условных плотностей 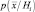 . Из множества различных функций плотности наибольшее значение имеет многомерная нормальная плотность распределения по следующим соображениям.
. Из множества различных функций плотности наибольшее значение имеет многомерная нормальная плотность распределения по следующим соображениям.
1. Многочисленные эксперименты и практические исследования говорят о чрезвычайно широком распространении названной плотности во многих практических ситуациях.
2. В силу центральной предельной теоремы при условии, что рассматриваемый признак есть по существу результат сложения большого количества примерно равнозначных явлений (ток – сумма электронов, тепловое движение – сумма перемещений атомов и т.п.), его распределение, по крайней мере в асимптотике, стремится к нормальному.
3. Многомерная нормальная плотность распределения дает подходящую модель для одного важного случая, когда значения векторов признаков x для данного класса представляются непрерывнозначными, слегка искаженными версиями единственного типичного вектора, или вектора-прототипа m. Именно этого ожидают, когда классификатор выбирается так, чтобы выделять те признаки, которые, будучи различными для образов, принадлежащих различным классам, были бы, возможно, более схожи для образов из одного и того же класса.
4. Немаловажную роль при использовании нормальной плотности играет удобство ее аналитического представления и операций над ней.
Многомерная нормальная плотность распределения в общем виде представляется выражением
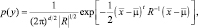 (2.6.1)
(2.6.1)
где  есть d-компонентный вектор-столбец;
есть d-компонентный вектор-столбец;  – есть d-компонентный вектор среднего значения; R – ковариационная матрица размера d×d;
– есть d-компонентный вектор среднего значения; R – ковариационная матрица размера d×d; 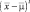 – транспонированный вектор
– транспонированный вектор 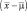 ; R–1 – матрица, обратная R, а |R| – детерминант матрицы R. Для простоты выражение (1.6.1) часто записывается сокращенно в виде
; R–1 – матрица, обратная R, а |R| – детерминант матрицы R. Для простоты выражение (1.6.1) часто записывается сокращенно в виде 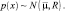
Вектор 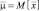 представляет собой вектор математических ожиданий вектора
представляет собой вектор математических ожиданий вектора  , а матрица
, а матрица 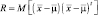 – матрицу ковариаций вектора
– матрицу ковариаций вектора  , (М[ ] – операция вычисления математического ожидания).
, (М[ ] – операция вычисления математического ожидания).
Ковариационная матрица R всегда симметрична и положительно полуопределена. Ограничимся рассмотрением случаев, когда R положительно определена, так что ее детерминант строго положителен. Диагональный элемент матрицы R представляет собой дисперсию Rii = σii, а недиагональный элемент Rij есть ковариация xi и xj. Если xi и xj статистически независимы, то Rij = 0. Если все недиагональные элементы равны нулю, то 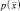 сводится к произведению одномерных плотностей компонент вектора
сводится к произведению одномерных плотностей компонент вектора  .
.
Многомерная нормальная плотность распределения полностью определяется d + d(d + 1)/2 параметрами – элементами вектора среднего значения  и независимыми элементами ковариационной матрицы R. Выборки нормально распределенной случайной величины имеют тенденцию попадать в одну область или кластер. Центр кластера определяется вектором среднего значения, а форма – ковариационной матрицей. Из соотношения (1.6.1) следует, что точки постоянной плотности образуют гиперэллипсоиды, для которых квадратичная форма
и независимыми элементами ковариационной матрицы R. Выборки нормально распределенной случайной величины имеют тенденцию попадать в одну область или кластер. Центр кластера определяется вектором среднего значения, а форма – ковариационной матрицей. Из соотношения (1.6.1) следует, что точки постоянной плотности образуют гиперэллипсоиды, для которых квадратичная форма 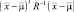 постоянна. Главные оси этих гиперэллипсоидов задаются собственными векторами R, причем длины осей определяются собственными значениями. Величину
постоянна. Главные оси этих гиперэллипсоидов задаются собственными векторами R, причем длины осей определяются собственными значениями. Величину
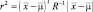
называют квадратичным махаланобисовым расстоянием от  до
до  . Линии постоянной плотности, таким образом, представляют собой гиперэллипсоиды постоянного махаланобисова расстояния
. Линии постоянной плотности, таким образом, представляют собой гиперэллипсоиды постоянного махаланобисова расстояния  . Объем этих гиперэллипсоидов служит мерой разброса выборок относительно среднего значения.
. Объем этих гиперэллипсоидов служит мерой разброса выборок относительно среднего значения.
Как мы показали выше, классификация с минимальным уровнем ошибки может осуществляться посредством разделяющих функций вида
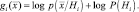
Когда многомерная плотность 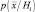 нормальна, согласно выражению (2.6.1) получаем
нормальна, согласно выражению (2.6.1) получаем
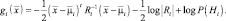 (2.6.2)
(2.6.2)
Последнее слагаемое определяется априорными вероятностями гипотез. Мы его учитывать не будем, т.к. названное слагаемое может быть добавлено на любом этапе работы алгоритма.
Рассмотрим ряд частных случаев.
1. Признаки статистически независимы и имеют одинаковую дисперсию
R = σ2E,
где E – единичная матрица.
В этом случае разделяющая функция сводится к вычислению эвклидова расстояния между вектором признаков и каждым вектором математических решений. Решение выбирается в пользу той гипотезы, для которой названное расстояние минимально.
 (2.6.3)
(2.6.3)
где 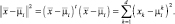 (2.6.4)
(2.6.4)
Такой классификатор называют классификатором по минимуму расстояния. Если каждый из векторов средних значений считать идеальным прототипом или эталоном для образов своего класса, то это по существу будет процедура сравнения с эталоном.
Если априорные вероятности не равны, то, согласно соотношениям (2.6.2) и (2.6.3), квадрат расстояния (2.6.4) должен быть нормирован по дисперсии (поделен на 2σ2) и смещен на величину logP(Hi); поэтому в случае, когда вектор  одинаково близок к двум различным векторам средних значений, при принятии решения следует предпочесть класс, априори более вероятный.
одинаково близок к двум различным векторам средних значений, при принятии решения следует предпочесть класс, априори более вероятный.
Произведя перемножение в формуле (2.6.2) и отбросив одинаковое для всех i слагаемое, приходим к линейной разделяющей функции:
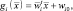 (2.6.5)
(2.6.5)
где 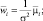
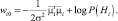
Классификатор, основанный на использовании линейных разделяющих функций, называется линейной машиной.
2. Ковариационные матрицы для всех классов одинаковы Ri = R.
Это соответствует ситуации, при которой выборки попадают внутрь гиперэллипсоидальных областей (кластеров) одинаковых размеров и формы, с вектором средних значений в центре каждой.
После того как мы пренебрегаем не зависящими от i слагаемыми, получаем разделяющие функции вида
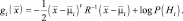 (2.6.6)
(2.6.6)
Если априорные вероятности для всех М классов равны, то последним слагаемым в формуле (2.6.6) можно пренебречь. Оптимальное решающее правило в таком случае снова оказывается очень простым: для классификации вектора признаков следует определить квадратичное махаланобисово расстояние от  до каждого из М векторов средних значений и отнести
до каждого из М векторов средних значений и отнести  к классу, соответствующему ближайшему среднему значению. Как и прежде, в случае неравных априорных вероятностей, при принятии решения несколько большее предпочтение отдается классу, априори более вероятному.
к классу, соответствующему ближайшему среднему значению. Как и прежде, в случае неравных априорных вероятностей, при принятии решения несколько большее предпочтение отдается классу, априори более вероятному.
После раскрытия квадратичной формы и отбрасывания слагаемых, не изменяющихся при разных значениях i, получаем выражения:
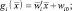 (2.6.7)
(2.6.7)
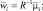
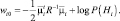
3. Произвольные корреляционные матрицы Ri.
В общем случае многомерного нормального распределения ковариационные матрицы для каждого класса разные. В этом случае разделяющие функции получаются квадратичными:
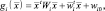 (2.6.8)
(2.6.8)
где 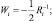
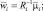
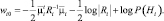
Таким образом, в зависимости от ситуации (независимые признаки, одинаковые ковариационные матрицы, различающиеся ковариационные матрицы) решение принимается в пользу той гипотезы, для которой выражение решающей функции (2.6.6), (2.6.7) и (2.6.8) соответственно максимально.