
Научная электронная библиотека
Монографии, изданные в издательстве Российской Академии Естествознания

2.7. Оценка параметров по максимуму правдоподобия. Обучение с учителем
В практических условиях апостериорные плотности вероятностей 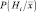 , как правило, либо неизвестны вообще, либо известны с точностью до ряда параметров. В то же время обычно имеется набор так называемых обучающих выборок, достоверно принадлежащих каждому из распознаваемых классов. Число этих выборок зачастую достаточно мало, чтобы вынести решение о функциональном виде требуемых плотностей вероятностей, но достаточно велико для построения оценок параметров названных плотностей, если их функциональный вид предполагается известным.
, как правило, либо неизвестны вообще, либо известны с точностью до ряда параметров. В то же время обычно имеется набор так называемых обучающих выборок, достоверно принадлежащих каждому из распознаваемых классов. Число этих выборок зачастую достаточно мало, чтобы вынести решение о функциональном виде требуемых плотностей вероятностей, но достаточно велико для построения оценок параметров названных плотностей, если их функциональный вид предполагается известным.
Допустим, что есть основания предполагать, что плотность вероятности 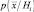 имеет нормальное распределение со средним значением
имеет нормальное распределение со средним значением  и ковариационной матрицей Ri, хотя точные значения названных величин точно неизвестны.
и ковариационной матрицей Ri, хотя точные значения названных величин точно неизвестны.
В этом случае решение принимается в соответствии с теми же принципами и правилами, что и в разделе 2.6, где в формулы (2.6.5), (2.6.6) и (2.6.8) подставляются не точно известные значения  и Ri, а их оптимальные в каком-то смысле оценки. Среди таких оценок наилучшими в практических ситуациях свойствами обладают оценки, полученные по методу максимального правдоподобия.
и Ri, а их оптимальные в каком-то смысле оценки. Среди таких оценок наилучшими в практических ситуациях свойствами обладают оценки, полученные по методу максимального правдоподобия.
Рассмотрим оценку по методу максимального правдоподобия. Предположим, что множество имеющихся обучающих выборок разбито на М классов X1, X2, …, XM, причем выборки в каждом Xi статистически независимы и имеют плотность распределения 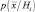 . Будем считать, что плотность
. Будем считать, что плотность 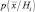 задана в параметрической форме, т.е. известно ее аналитическое выражение с точностью до неизвестного векторного параметра Q. Например, нам известно, что выборки подчиняются нормальному закону распределения с неизвестным вектором математических ожиданий
задана в параметрической форме, т.е. известно ее аналитическое выражение с точностью до неизвестного векторного параметра Q. Например, нам известно, что выборки подчиняются нормальному закону распределения с неизвестным вектором математических ожиданий  и ковариационной матрицей Ri. В этом случае компоненты вектора Q составлены из компонент
и ковариационной матрицей Ri. В этом случае компоненты вектора Q составлены из компонент  и Ri.
и Ri.
Для того чтобы в явном виде показать зависимость от неизвестных параметров, запишем плотность вероятностей в виде 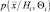 . Задача оценки неизвестных параметров заключается в определении их величин по наблюдаемым данным наилучшим образом.
. Задача оценки неизвестных параметров заключается в определении их величин по наблюдаемым данным наилучшим образом.
Будем считать, что выборки, принадлежащие наблюдаемым данным Xi, не содержат информации о векторе параметров Θj, т.е. предполагается функциональная независимость параметров, принадлежащих разным классам. Последнее обстоятельство дает возможность рассматривать отдельно каждый класс.
Пусть X содержит n выборок 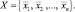 Так как выборки получены независимо, имеем:
Так как выборки получены независимо, имеем:
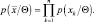 (2.7.1)
(2.7.1)
Рассматриваемая как функция от Q плотность 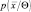 называется функцией правдоподобия. Оценка по максимуму правдоподобия величины Q есть такая величина
называется функцией правдоподобия. Оценка по максимуму правдоподобия величины Q есть такая величина  , при которой выражение (2.7.1) максимально.
, при которой выражение (2.7.1) максимально.
На практике эквивалентным, но более простым по своим вычислениям является отыскание максимума не собственно плотности вероятности, а ее логарифма. Если ввести оператор градиента:

где p – размерность вектора параметров и обозначить функцию логарифма правдоподобия:
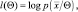
то оптимальная оценка вектора параметров Q может быть получена из решения уравнения:
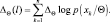
Применим полученные результаты для многомерного нормального распределения. Начнем со случая, когда неизвестно только среднее значение. Запишем выражение для логарифма функции правдоподобия и оператора градиента:
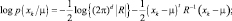
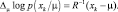
С учетом (2.7.1) получаем уравнение
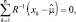
из которого следует:
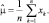 (2.7.2)
(2.7.2)
Полученный результат свидетельствует о том, что оценка по максимуму правдоподобия равна среднему арифметическому выборок. Для ковариационной функции аналогичным образом может быть получена ее оценка по максимуму правдоподобия, которая имеет вид:
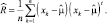 (2.7.3)
(2.7.3)
Полученные результаты (2.7.2) и (2.7.3) представляются совершенно естественными и интуитивно понятными.
В результате процедура классификации выглядит следующим образом.
1. Этап обучения. По обучающим выборкам строятся оценки математических ожиданий и ковариационных функций (формулы (2.7.2) и (2.7.3)) для каждой из М конкурирующих гипотез.
2. Далее вычисляются М решающих функций: формулы (2.6.5), (2.6.7), (2.6.8).
3. Решение принимается в пользу той гипотезы, для которой решающая функция максимальна.
Рассматриваемые решающие функции, основанные на вычислении взвешенных расстояний между наблюдаемым вектором признаков и вектором математических ожиданий, полученным на этапе обучения, дают хорошие результаты в случае, когда вектор признаков имеет нормальное или близкое к нему распределение.