
Научная электронная библиотека
Монографии, изданные в издательстве Российской Академии Естествознания

2.1. Стандартное отклонение среднего выборочного значения (ошибка среднего) и доверительный интервал
Результаты измерений обычно показывают с так называемой «средней статистической ошибкой средней величины» и для нашего случая (см. табл. 1.1) это будет запись: «высота сеянцев в опыте составила 5,0 ± 0,28 см». Словосочетание «средняя статистическая ошибка» обычно сокращают до названия «ошибка среднего» или просто «ошибка», обозначают буквой m и определяют по очень простой формуле. Для итогов упомянутой таблицы, где расчеты по 25 высотам дали значение δ = 1,42 см, эта ошибка составит:
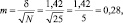 (2.1)
(2.1)
|
где δ – |
стандартное отклонение; |
|
N – |
число наблюдений или объем выборки, шт. |
Если объем выборки взять 100 шт., то ошибка снизится в 2 раза: 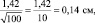 а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
Рассмотрим эту «среднюю статистическую ошибку» (далее просто ошибка) подробно, так как именно в ней скрыто понимание того, что называют статистическим мышлением. Интуитивно мы понимаем, что малая выборка дает большую ошибку, т.е. неточное определение среднего значения. Последний термин настолько привычен, что мы даже не задумываемся о том, что его правильное и полное название «среднее выборочное значение», т.е. среднее, определяемое в некоторой выборке. И выборки могут быть очень разные по численности. Начнем с самых малых. Например, что произойдет с ошибкой, если объем выборки сократить до 2 измерений? Такие выборки бывают, например, в почвенных исследованиях, когда каждое измерение достается дорогой ценой. Для этого вернемся к рис. 1.1. На нем стандартное отклонение ±δ, которое отражает разброс значений вокруг среднего в левую и правую сторону в виде холма, наблюдается при объеме выборки 1 шт. В этом случае ошибка среднего выборочного значения будет равна стандартному отклонению: m = δ = 1,42. С увеличением N ошибка уменьшается:
при объеме выборки N = 2 ошибка будет
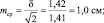
при объеме выборки N = 4 ошибка будет
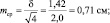
при объеме выборки N = 16 ошибка будет
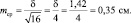
Важно понять, что ряд распределения частот этих выборочных средних будет постепенно как бы съеживаться и приближаться к центру, где находится так называемое «генеральное» среднее. Поясним, что в математике генеральное среднее значение называется математическим ожиданием и его обозначают буквой «М». Например, это может быть средняя высота, рассчитанная по всем измеренным в теплице сеянцам, или среднее число семян в 1 шишке у дерева после подсчета семян во всех собранных с дерева шишках (50, 100, 500 и т.д., т.е. весьма небольшая генеральная совокупность). Распределение частот значений выборочных средних, которых может быть множество, будет иметь форму такого же холма, как и распределение единичных значений на рис. 1.1. При этом, если выборка будет из 1 шт., то холм будет в точности таким же, но при выборках из 2 шт. его форма съежится в 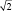 = в 1,41 раза; при выборках из 4 шт. –
= в 1,41 раза; при выборках из 4 шт. –
в 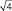 = в 2 раза; при выборках из 9 шт. – в
= в 2 раза; при выборках из 9 шт. – в 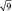 = в 3 раза и т.д.
= в 3 раза и т.д.
Для этих сокращающихся рядов распределения выборочных средних можно рассчитать свое, особое стандартное отклонение. Вероятно, чтобы не путать его со СТАНДОТКЛ, его стали называть по-другому, т.е. «средней статистической ошибкой средней величины». Чем больше по объему выборки, тем короче ряд распределения средних значений этих выборок с его «хвостами» в левую и правую сторону, и тем меньше величина этого особого стандартного отклонения. Закон распределения частот выборочных средних точно такой же, и имеет те же свойства: в пределах ±2m находится 95 % всех значений выборочных средних, в пределах ±3m – 99,5 %, а в пределах ±4m находится 100 % всех значений xср. Форма этого распределения меняется от пологой при малых выборках до очень крутой, вплоть до «схлопывания» в центре при выборках большого объема, когда ошибка среднего стремится к нулю.
Здесь следует пояснить, что, на наш взгляд, словосочетание «средняя статистическая ошибка средней величины», сокращаемое до «ошибки среднего значения» или просто до «ошибки», вводит нас в некоторое заблуждение, так как мы привыкли со школы, что ошибки надобно исправлять. Более правильным, вместо слов «ошибка среднего значения», будет использование слов «стандартное отклонение выборочных средних значений от генерального среднего». Не случайно математики выбрали для обозначения величины этого отклонения букву «m», а для обозначения генерального среднего (математического ожидания) – букву «М». Слова для объяснения этих сложных явлений могут быть разными, но и у математиков, и у биологов есть единодушие в понимании статистического смысла, лежащего за этими буквенными символами. Вообще, лучше было бы ввести некий иной термин вместо слов «ошибка» или «отклонение», так как они изначально имеют в нашем сознании иной смысл; на наш взгляд, более всего подходит слово «скачок» (чем сильнее отскакивает выборочное среднее от генерального среднего, тем реже оно встречается). Но так уж получилось, что не нашлось нейтрального (иностранного) слова, и слово «ошибка» традиционно используют, и мы также будем его использовать; важно понимать его иной, чем в обыденном употреблении, математический и статистический смысл.
Для самого точного определения средней высоты сеянцев нужно измерять все растения в питомнике, и тогда мы получим «генеральное среднее значение». Но так не делают, а измеряют несколько сотен растений в разных местах и этого бывает достаточно для определения среднего выборочного значения с приемлемой точностью. В нашем примере при 100 растениях ошибка его определения составит 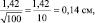 а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
Вообще, точность опыта не самоцель; гораздо важнее сократить численность (объем) выборки до минимума. Представим себе, что средняя высота сеянцев xср = 5,0 см, а ее ±δ = 1,42 см, рассмотренные выше, получены при измерении 1000 растений потомства сосны, например, из Кунгура. Поделив ±δ на корень из 1000 получаем ошибку опыта m = ±0,045 см. Далее получаем точность опыта
Р = m/xср×100 = 0,045/5,0×100 = 0,9 %.
Точность получилась очень высокой. Но в питомнике есть потомства и из других мест и такой уровень точности совершенно не нужен, так как нужно узнать еще высоты сеянцев, например, из Очера, Осы, Добрянки и других районов. Если выборку из 1 тыс. растений снижать, то будет увеличиваться ошибка в определении средней высоты. И нужно найти приемлемую величину такой ошибки, которая позволит нам, тем не менее, уверенно утверждать, что это потомство растет быстрее, либо медленнее других. Причем происхождений может быть несколько сотен и минимизация выборок крайне важна, так как масштабы работ ограничены физическими возможностями бригады селекционеров. Следовательно, надо сокращать объем выборки. Как это сделать правильно?
Рассмотрим два потомства. Первое – это упомянутые сеянцы происхождением из Кунгура (хср1), второе – сеянцы из Кизела с хср2 = 6,0 см и δ2 = ± 1,0 см (превышение высоты на 20 %). Надо это превышение доказать. При выборках из 100 растений ранее определенная ошибка m1 была равна 0,14 см, вторая ошибка m2 после расчетов по формуле (2.1) составит 0,1 см. По закону нормального распределения 99,5 % всех возможных значений этих средних хср1 и хср2 будут в пределах «плюс-минус три ошибки», что можно показать графически (рис. 2.1) или в виде формул:
хср1 ± 3m1 = 5,0 ± 3×0,14 = 5,0 ± 0,4 см
и
хср2 ± 3m2 = 6,0 ± 3×0,1 = 6,0 ± 0,3 см.
Возможные теоретические значения средних в генеральной совокупности не перекрывают друг друга, значит, различие достоверно. А если сократить выборки до 50 сеянцев? Тогда 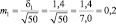 и
и 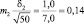 и пределы колебаний возможных значений средних будут:
и пределы колебаний возможных значений средних будут:
хср1 ± 3m1 = 5,0 ± 3×0,20 = 5,0 ± 0,6 см;
хср2 ± 3m2 = 6,0 ± 3×0,14 = 6,0 ± 0,3 см.

Рис. 2.1. Средние значения по выборкам из 100 растений и их тройные ошибки (пределы возможных значений выборочных средних в 99,5 % случаев)
Снова вынесем эти пределы на график (рис. 2.2).

Рис. 2.2. Средние значения при N = 50 растений и их тройные ошибки
Как видим, пределы сблизились и если еще сократить выборки, то они перекроются. Можно ли далее снижать объем выборки?
Можно, но здесь вступает в силу так называемое условие безошибочного прогноза. Мы это условие задали на уровне 99,5 % и для этого взяли ±3m для распределения ошибок. Но можно взять уровень пониже, с пределами ±2δ (уровень 95 %) и даже с пределами ±1,7δ (уровень 90 %).
При выборках из 25 штук сеянцев, получаем две ошибки: 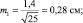
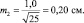 Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
хср1 ± 2m1 = 5,0 ± 2×0,28 = 5,0 ± 0,56 см;
хср2 ± 2m2 = 6,0 ± 2×0,20 = 6,0 ± 0,40 см.
Выносим эти пределы опять на график (рис. 2.3).
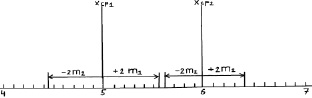
Рис. 2.3. Средние значения при N = 25 растений и их двойные ошибки (пределы возможных значений средних в 95 % случаев)
Как видим, просвет все еще есть, и поэтому между возможными значениями средних высот сеянцев в других выборках из происхождений Кунгур и Кизел различия будут опять доказаны. Но уровень доказательства понизился до 95 %, и для 5 % оставшихся случаев нет гарантии, что различия будут иметь место при выборке из 25 растений. Их может и не быть, но эту вероятность в 5 % мы допускаем.