
Научная электронная библиотека
Монографии, изданные в издательстве Российской Академии Естествознания

2.3. Объем выборки и объединение данных разных опытов
Вопрос объема выборки возникает в любом эксперименте. Но в селекции он ключевой и, вероятно, самый сложный. Физические возможности исследователя ограничены, и приходится выбирать – либо малые выборки и много вариантов, либо точное значение показателя и меньшее число вариантов. Ввиду сложности освоение данного вопроса для бакалавров мы ограничиваем только первым способом планирования объема выборки.
Для оценки точности полученного среднего значения используют так называемую «точность опыта» (точность определения среднего значения). Ее обозначают буквой «р» или «Р» и определяют по формуле:
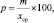 %, (2.3)
%, (2.3)
|
где р – |
точность опыта, %; |
|
m – |
статистическая ошибка выборочной величины; |
|
хср – |
среднее значение признака в выборке. |
При планировании выборки в несложных опытах чаще всего применяют следующую простую формулу:
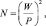 шт., (2.4)
шт., (2.4)
|
где N – |
объем выборки (число наблюдений); |
|
Р – |
точность опыта, %; |
|
W – |
коэффициент вариации, определяемый по формуле: |
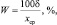 (2.5)
(2.5)
|
где δ – |
стандартное отклонение; |
|
хср – |
среднее значение признака в выборке. |
Обычно принимают Р = ±5,0 %. Так, если вариация W = ±20 %, то получаем выборку 16 шт., а если вариация будет ±30 %, то выборка увеличится до 36 шт.
Однако данная формула учитывает выполнение указанной точности лишь для 68 % выборок, т.е. в пределах плюс-минус одно стандартное отклонение в ряде распределения этих средних. Напомним, что для множества средних выборочных значений совершенно также, как и для единичных измерений, можно построить частотный ряд, который будет в виде округлого холма и будет подчиняться закону нормального распределения. Поэтому, чтобы охватить указанной точностью опыта не 68 %, а 95 % выборок, в числитель формулы (2.4) вводят критерий Стьюдента t0,95 = 2,0, а для охвата 99 % выборок это значение t увеличивают до 2,6. Тогда расчеты для Р = ±5 % при t0,95 = 2,0 дают объем выборки уже 64 шт. Заметим, что в лесную селекцию (вероятно, из лесной таксации) перекочевало убеждение, что для надежных оценок высоты и диаметра нужна точность в ±2–3 %. Тогда для точности ±3,0 % при t0,95 = 2,0 нужна выборка уже из 178 растений. Как видим, даже эта простая формула дает разные решения касательно объема выборки.
Какая же точность опыта нужна, и почему ее часто принимают в ±3–5 %? Ответ на этот вопрос лежит в доказательстве достоверности превышения роста лучшего потомства, например, на 10 %. При вариации W = ±20 % и объеме выборки 64 шт. для такого превышения критерий Стьюдента составит t = 2,83 > t0,99 = 2,63. Различие оказалось высоко достоверно. Если же снизить выборку до 33 шт., то различие будет доказано на среднем уровне при t = 2,03 > t0,95 = 2,0 и этот уровень обычно считают достаточным.
При испытаниях на быстроту роста превышение на 10 % часто принимают как критерий отбора, и выборка из 33 растений его доказывает при вариации W = ±20 % и при t0,95 = 2,0. Однако тут сразу возникают вопросы:
– мы доказываем наличие некоего превышения вообще, а каким будет это превышение в точном его значении, остается неизвестным;
– можно ли снизить критерий до t0,90 = 1,65?
И это далеко не все вопросы. Например, проводится сложный опыт с испытаниями семенами нескольких урожаев для расчета общей комбинационной способности (ОКС), причем в тест-культурах в разных условиях. Как обобщать такие сложные опыты?
С этой целью данные переводят в относительные величины, для чего в каждом испытании нужен контрольный вариант, принимаемый за 100 %. В результате разнородные опыты объединяют и получают общую среднюю оценку роста потомства в % от контроля. Если контроля нет, то рассчитывают среднюю величину в одном опыте или в его блоке, и уже ее принимают за 100 % (однако тогда эффект селекции будет совершенно неясен). Наиболее точным является «парный» контроль, когда рядом с опытной делянкой высаживают контроль. Применяют его редко и обычно контроль сокращают до 8–10 % от числа и объемов выборок всех вариантов опыта.
Минимизация выборки крайне важна, так как позволяет резко увеличить число вариантов. Для лучших потомств обычно принимают их высоту 110 % от высоты контроля. Но чтобы доказать это превышение на 10 %, выборка должна иметь почти нулевую ошибку, что практически недостижимо, так как нужны тысячи растений. Поэтому высоту для лучших потомств берут заведомо больше 110 %, например 113–115 %, и это превышение на 3–5 % называют «наименьшая существенная разность» (НСР).
Первый способ планирования выборки как раз и основан на подборе ее объемов для доказательства выбранной НСР при условии tф ≥ t0,95 = 1,96.
Возьмем реальный пример – испытания 246 семей ели в 21–23-летнем возрасте, где средняя вариация высот внутри семей составила в среднем 28 %. С возрастом эта вариация может быть разной, поэтому рассмотрим два сценария планирования, при вариации 25 и 30 %. Поясним, что в этом опыте семей с высотой от 115 % оказалось 9,3 %, с высотой от 114 % – в 1,1, а семей с высотой от 113 % было уже в 1,3 раза больше. Все они – лучшие, но чтобы правильно их отобрать, нужны разные выборки. Так, при вариации 25 % и снижении высоты их отбора от 115 к 113 % общее число растений для 100 опытных семей возрастает в 3,8 раза (табл. 2.2).
Это увеличение в 3,8 раза было бы оправдано, если бы сильно возрастала и доля лучших семей, но она выросла лишь в 1,3 раза. Поэтому при планировании лучше увеличить число семей в те же 1,3 раза, но отбирать их по большей высоте в 115 %, а выборку оставить минимальной (110 шт.). В результате будет отобрано точно такое же число лучших потомств, но объем работ увеличится лишь в 1,3, а не в 3,8 раза. Еще большее увеличение объема работ – в 4,3 раза – получаем в неблагоприятном сценарии.
Если поделить полученный минимальный объем выборки на 4 испытания, то получим в каждом ≈ 30 шт. при вариации 25 % и 56 шт. – при вариации 30 %. Но следует учесть, что можно селекционировать и устойчивые потомства, с вариацией высот около 20 %. Поэтому выборки вполне можно снизить в каждом из 4-х испытаний даже меньше 20 шт.
Таблица 2.2
Планирование испытательных культур 100 потомствами с целью отбора семей, достоверно превышающих контроль на 10 % и более
|
Высота лучших семей, % |
Число растений во всех опытах* |
Ошибка среднего, % |
Доля лучших |
Общее число |
|||
|
шт. |
% |
% |
увеличение доли, раз |
тыс. шт. |
увеличение, раз |
||
|
Благоприятный сценарий, коэффициент вариации высот 25 % |
|||||||
|
115 |
110 |
100 |
2,4 |
9,3 |
1 |
11,8 |
1 |
|
114 |
200 |
182 |
1,8 |
10 |
1,1 |
20,8 |
1,8 |
|
113 |
435 |
395 |
1,2 |
12 |
1,3 |
44,3 |
3,8 |
|
Неблагоприятный сценарий, коэффициент вариации высот 30 % |
|||||||
|
115 |
167 |
152 |
2,3 |
9,3 |
1 |
17,5 |
1 |
|
114 |
296 |
269 |
1,7 |
10 |
1,1 |
30,4 |
1,7 |
|
113 |
740 |
673 |
1,1 |
12 |
1,3 |
74,8 |
4,3 |
Примечания:
* – желательны два типа условий и минимально два урожая семян (всего 4 испытания);
** – добавляются растения в контроле (800 шт.).
Второй и третий способы планирования выборки более сложные; их рекомендуется прочитать магистрантам, а также селекционерам при разработке своих конкретных программ селекции на быстроту роста.
Второй способ планирования выборки совершенно иной. В нем снижают выборку на основе генератора случайных чисел, далее сравнивают различия между семьями в дисперсионном анализе и подбором объемов выборок выполняют условие достоверности различий для 95 % случаев. Его применили в республике Коми для сосны (Туркин, Федорков, 2007) и в Ленинградской и Псковской обл. для ели (Бондаренко, Жигунов, 2016). В результате рекомендована численность 200 растений на потомство. С учетом сохранности 50–60 % к 20 годам как раз и получается выборка из 100–110 измеряемых деревьев, или 25–30 растений в каждом опыте (см. табл. 2.2).
Подобных расчетов в лесной селекции ранее не было, так как ее задачу рассматривали с приматом высокой ценности плюс-деревьев, и выборку на потомство доводили до максимума. Вышеприведенный пример показывает, насколько не оправданы такие затраты. Но при сокращении выборки на семью в каждом из четырех испытаний до ≈ 30 шт. растений общее их число составит всего 110 шт. Для 100 семей с учетом контроля число измеряемых растений достигнет 11,8 тыс. (см. табл. 2.2). С учетом их сохранности 50 % в культуры следует высаживать примерно 24 тыс. саженцев. Наш опыт работы показал, что бригада из 4 человек весной в течение 22 календарных дней осуществила выкопку и посадку 50 тыс. саженцев с картированием 560 вариантов опыта на одном, и 400 вариантов – на втором участке, с высадкой от каждой семьи по 40–60 растений в 3–6 повторностей (Рогозин, Разин, 2012), а это уже заявка на высокую интенсивность селекции.
Третий способ еще более сложен, и разобраться в нем можно, только детально планируя весь процесс работы. Он рассматривает общую статистическую ошибку, получаемую как итог в серии опытов и разлагает (разделяет) ее далее на ряд ошибок, вызываемых следующими факторами:
– экологическими различиями (экологическая ошибка);
– генетическими отличиями семян (репродуктивная ошибка);
– вариацией высот внутри семей, округлением данных при измерениях и прочими случайными факторами (прочие ошибки).
Ниже будут приведены только итоговые результаты, а сами расчеты можно представить, если рассматривать всю массу измерений, где бывали случаи, когда семьи в одних условиях имели высоты 120 % и более, а в других условиях их высоты оказывались на уровне лишь 80–90 %. Это будет экологическая ошибка. Репродуктивная ошибка появляется в результате генетической неоднородности семян, где корреляция высот семей от урожаев разных лет оказалась очень слабой (r = 0,16 ± 0,05), и высоты семей имели различия, близкие к различиям в разных почвенных условиях (далее эти корреляции будут рассмотрены в разделах 5.1 и 5.2). Ошибка эта получается из-за различий в генетическом пуле семян, который меняется год от года в зависимости от пыльцевой продуктивности, сроков цветения, вызревания пыльцы и т.д. Снизить ее невозможно. Но экологическую ошибку, т.е. вариацию из-за разных условий, можно снижать, выравнивая эти условия.
Величину статистических ошибок моделировали при разных сценариях – при 200, 50 и 20 растениях в одном потомстве (табл. 2.3).
Таблица 2.3
Статистические ошибки средней высоты в потомствах сосны в возрасте 3–5 лет, вызванные репродуктивной, экологической и случайной изменчивостью при разных сценариях планирования объема выборки, %
|
Показатели |
Число испытаний |
||||
|
1 |
2 |
3 |
4 |
5 |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
|
Виды ошибок: |
|||||
|
экологическая |
3,40 |
2,40 |
1,96 |
1,70 |
1,08 |
|
репродуктивная |
5,29 |
3,74 |
3,05 |
2,64 |
1,67 |
|
прочие |
1,13 |
0,80 |
0,65 |
0,50 |
0,32 |
|
в контроле при n = 400 |
1,00 |
0,71 |
0,58 |
0,55 |
0,32 |
|
в потомстве при n = 200 |
1,41 |
1,00 |
0,81 |
0,70 |
0,45 |
|
в потомстве при n = 50 |
2,83 |
2,00 |
1,63 |
1,41 |
0,89 |
|
в потомстве при n = 20 |
4,47 |
3,16 |
2,58 |
2,24 |
1,41 |
|
Статистическая сумма ошибок при числе растений в потомстве, шт: |
|||||
|
n = 200 |
6,6 |
4,7 |
3,8 |
3,3 |
2,1 |
|
n = 50 |
7,1 |
5,0 |
4,1 |
3,5 |
2,2 |
|
n = 20 |
7,9 |
5,6 |
4,5 |
3,9 |
2,5 |
|
Отношение к общей ошибке при n = 200: |
|||||
|
n = 200 |
100 |
100 |
100 |
100 |
100 |
|
n = 50 |
107 |
107 |
107 |
107 |
107 |
|
n = 20 |
119 |
119 |
119 |
119 |
119 |
|
Вклад ошибок при n = 200 шт. (отношение квадратов ошибок к общей ошибке), % |
|||||
|
экологическая |
26 |
26 |
26 |
26 |
27 |
|
репродуктивная |
64 |
64 |
64 |
64 |
64 |
|
прочие |
3 |
3 |
3 |
3 |
3 |
|
в контроле при n = 400 |
2 |
2 |
2 |
3 |
2 |
|
в потомстве при n = 200 |
5 |
5 |
5 |
4 |
5 |
|
Всего ошибок |
100 |
100 |
100 |
100 |
100 |
|
Вклад ошибок при n = 20 шт. (отношение квадратов ошибок к общей ошибке), % |
|||||
|
экологическая |
19 |
19 |
19 |
19 |
19 |
|
1 |
2 |
3 |
4 |
5 |
6 |
|
репродуктивная |
45 |
45 |
45 |
45 |
45 |
|
прочие |
2 |
2 |
2 |
2 |
2 |
|
в контроле при n = 400 |
2 |
2 |
2 |
2 |
2 |
|
в потомстве при n = 20 |
32 |
32 |
32 |
32 |
32 |
|
Всего ошибок |
100 |
100 |
100 |
100 |
100 |
Для лучшего понимания структуры ошибок, данные в ней представлены в сокращенном виде, без знаков ± и с округлением. Главным итогом расчетов оказалось то, что общая ошибка зависит не столько от объема выборки, сколько от числа испытаний. Так, при одном испытании и при числе растений n = 200 шт. статистическая сумма ошибок составит 6,6 %, а при n = 20 шт. она увеличивается всего лишь до 7,9 %.
Расчеты кажутся непонятными для одного испытания, где можно рассчитать только вариацию внутри семьи, далее вариацию между средними значениями у семей, и затем общую вариацию по всем растениям. И в одном опыте, конечно же, невозможно рассчитать вклад ошибок экологической и репродуктивной. Но как только мы проводим второе испытание, то эти ошибки появляются. А если они становятся известны, то можно рассчитать их долю и в одном, и в 3–5 испытаниях по известной формуле (2.1), по зависимости ошибки выборочного среднего от стандартного отклонения и числа наблюдений.
Особенно ценным в этих расчетах оказалось разделение ошибок экологической и репродуктивной. Их общий вклад при выборке 200 шт. составляет 26 + 64 = 90 %, и сокращается до 54 % при выборке 20 шт. растений. При этом вклад ошибки, зависимой только от объема выборки на семью, увеличивается с 5 до 32 % и становится уже сопоставим с экологической и репродуктивной ошибками (см. табл. 2.3).
По итогам этих расчетов можно выбрать в целом приемлемый объем выборки из 20–30 растений в одном испытании при условии, что будет еще 3–4 испытания. Средние высоты будут оценены в итоге по 80–110 растениям с ошибкой, обеспечивающей достоверное превышение на 10 % для потомств со средними высотами 115 % и более. При отборе потомств с меньшими высотами, например, от 114 и 113 %, объемы выборок увеличиваются до 200 и 435 измеряемых растений. В целом в этом примере для потомства сосны в возрасте 3–5 лет наиболее значительной оказывается репродуктивная ошибка, и она в 2,5 раза превышает ошибку экологическую.
Таким образом, как бы мы ни старались повысить точность большими выборками в одном испытании, эти усилия, по сути, напрасны, так как в следующих испытаниях на 90 % будут доминировать ошибки, вызываемые экологией и генетической неоднородностью семян. Для их снижения необходимы испытания несколькими урожаями семян и в разных условиях.