
Научная электронная библиотека
Монографии, изданные в издательстве Российской Академии Естествознания

1.5.2 Примеры задач экономики, решенных по методике Data Mining
Пример 1. Прогнозирование сбыта продукции предприятия малого бизнеса
В результате анализа показателей работы одного из потребительских обществ разработана система взаимосвязи и влияния 32 факторов управления деятельностью потребительского общества (на примере Потребительского общества «Пищекомбинат» j одного из районов Волгоградской области).
Ассортиментный ряд средней компании, занимающейся сбытом продукции, составляет сотни наименований. Поэтому построение индивидуальной модели для каждой товарной позиции не представляется возможным по многим причинам. Обычно строят модель для товарной группы, а распределение квот по каждой позиции проводят специальным образом на этапе разгруппировки. Поэтому перед построением моделей важно провести сегментацию товаров на группы. Легче всего в качестве отправной точки использовать имеющуюся маркетинговую сегментацию, или деление по производителям. В любом случае следует прибегнуть к опросу экспертов, чтобы узнать, какое деление наиболее эффективно с точки зрения задачи прогноза. При отсутствии каких-либо гипотез можно начать, как вариант, с сегментации по производителям.
Построение модели – наиболее сложная и трудоемкая часть получения прогноза. В целях упрощения работы аналитика в Deductor Studio все модели временных рядов делятся на три типа:
1) нелинейная модель на основе искусственной нейронной сети;
2) линейная модель на основе линейной регрессии, коэффициенты которой рассчитываются автоматически;
3)пользовательская модель.
Выбрана нейронная сеть, так как она способна смоделировать более сложные (нелинейные) зависимости. Нейронная сеть – совокупность нейронных элементов и связей между ними. Основной элемент нейронной сети - это формальный нейрон, осуществляющий операцию нелинейного преобразования суммы произведений входных сигналов на весовые коэффициенты:
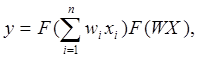 (1.7)
(1.7)
где 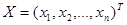 - вектор входного сигнала,
- вектор входного сигнала,
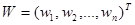 - весовой вектор,
- весовой вектор,
F - нелинейное преобразование.
Подбор весовых коэффициентов осуществляется в процессе обучения. Для обучения нейросети нужно подготовить набор обучающих данных. Нейронная сеть учится устанавливать связь между входами и выходами. В качестве метода обучения применяются специальные алгоритмы. Если сеть обучена хорошо, она приобретает способность моделировать неизвестную функцию, связывающую значения входных и выходных переменных, и впоследствии такая нейросеть используется для прогнозирования, когда по известным входам сети требуется получить неизвестные значения выходов.
Использование метода искусственного интеллекта позволяет исключить постоянное проведение расчетов, так как «обученная» модель нейронной сети работает по системному принципу «чёрного ящика». В нейросетевой модели перед аналитиком встает вопрос определения архитектуры нейронной сети, в частности, количество скрытых слоев и нейронов в них.
АналитическаяплатформаDeductorпозволяетрешитьзадачу прогнозирования сбыта продукции,чему помогают создание хранилища данных и аналитическая OLAP-отчетность.Помимо этого необходимы моделипрогнозапродаж–онистановятсяглавной частью аналитическогорешениядля управления сбытом товаров. Для прогнозирования сбыта продукции в Deductor проводится ряд экспериментов на моделях нейронных сетей различной архитектуры. Для проведения экспериментов выбрана модель «Многослойная нейронная сеть».
После изучения предметной области в качестве исходных данных были выбраны факторы: вид продукции, цена продажи, цена закупки, скидка, объем продаж, средний уровень товарооборота, уровень спроса, уровень предложения. Прогнозирование проводится по целевому фактору «Прибыль». Средний уровень товарооборота, уровень спроса, уровень предложения, вид продукции имеют назначение: информационные, как показано на рис. 1.6.
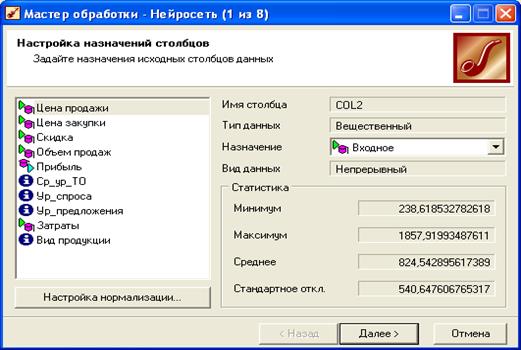
Рисунок 1.6 – Настройка столбцов данных
После разбиения исходного набора данных на подмножества проводится настройка структуры искусственной нейросети. Для первого эксперимента выбрана модель нейросети с архитектурой (5-2-1). Диаграмма рассеивания результатов моделирования определяет допустимость применения конкретной модели нейронной сети для прогнозирования сбыта продукции.
В результате проведения ряда экспериментов на моделях с изменением настроек, структуры и (или)набора входных параметров определяется оптимальная модель нейронной сети. Например, модель нейронной сети, показанная нарис. 1.7, может считаться оптимальной в ряде проведенных экспериментов, что видно из диаграммы рассеяния на рис. 1.8.

Рисунок 1.7 – Модель нейросети 3 (8-2-1)
Так как полученные значения не выходят за границы допустимой точности решения, то модель нейросети можно использовать для прогнозирования сбыта продукции по целевому фактору – прибыль при входных данных: цена продажи, цена закупки, скидка, объем продаж, средний уровень продаж, уровень спроса, уровень продаж, затраты.
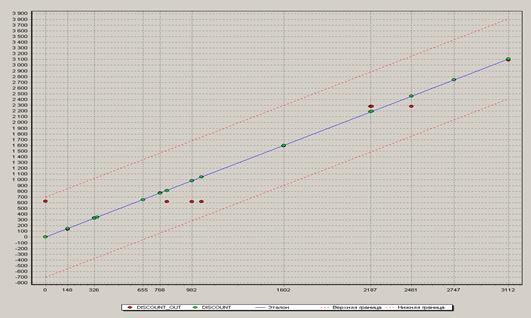
Рисунок 1.8 – Диаграмма рассеяния
Если, например, имитационная модель экономики предприятия позволяет на компьютере проводить только рутинные расчёты, а принимает решение (так называемое в человеко-машинной системе «Лицо, принимающее решение») – руководитель, то в отличие от данной модели компьютерные средства моделирования на искусственных нейронных сетях выдают результат для конкретной моделируемой ситуации. Руководитель ставит цель прогнозирования и получает модельное решение, подсказывающее - как надо действовать в той или иной ситуации.
Пример 2. Анализ оценки недвижимости с применениемискусственных нейронных сетей
Целью работы является анализ оценки недвижимости города Волгограда, основанный на моделировании на искусственных нейронных сетях. Исследовался прогнозный показатель потребности в жилых домах за год. Оценка проводилось с использованием аналитическойпрограммной платформыDeductor для анализа экономических данных, в том числе для моделирования на искусственных нейронных сетях. Эффективной моделью нейронных сетей для решения задач прогнозирования является «многослойный перцептрон». При обучении искусственных нейронных сетей алгоритмом обратного распространения ошибки искусственная нейросеть способна произвести наиболее вероятный прогноз при условии, что обучающая выборка является точной и достаточно объемной для обучения.
За основу данных для обучающей выборки брались статистические данные из сайта федеральной службы государственной статистики с 1995 по 2004 год, представленные (выборочно) в табл. 1.1. В качестве входной информации использовались такие показатели как:
- средний коэффициент роста стоимости квартиры за год (%);
- средняя стоимость аренды участка земли (руб. за
- средняя величина затрат на возведение жилого фонда (тыс. руб. за кв. метр);
- ввод жилых домов (млн. кв. м. в год).
Таблица 1.1 – Статистические данные
|
Тип вы-бор-ки |
№ п.п |
Год/ полу-годие |
Средняя стоимость аренды участка земли(%) |
Затраты на возведение (тыс. руб.) |
Ввод жилых домов (млн. кв.м. в год) |
Коэффициент изменения стоимости квартиры (%) |
Потребно-сть в жилых домах (условно) |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
Обучающая выборка |
1 |
1995/1 |
200 |
12100 |
41,0 |
110,3 |
7698 |
|
2 |
1995/2 |
203 |
12230 |
41,0 |
110,3 |
7473 |
|
|
3 |
1996/1 |
206 |
12360 |
34,3 |
110,8 |
7248 |
|
|
4 |
1996/2 |
209 |
12490 |
34,3 |
110,8 |
7004 |
|
|
5 |
1997/1 |
212 |
12620 |
32,7 |
111,3 |
6760 |
|
|
….. |
…….. |
……… |
…….. |
……. |
……. |
……. |
|
|
12 |
2000/2 |
233 |
13530 |
30,3 |
106,2 |
5138 |
|
|
13 |
2001/1 |
236 |
13660 |
31,7 |
118,9 |
4857 |
|
|
14 |
2001/2 |
239 |
13790 |
31,7 |
118,9 |
4642 |
|
|
Тестовая |
15 |
2002/1 |
242 |
13920 |
33,8 |
122,9 |
4428 |
|
16 |
2002/2 |
245 |
14050 |
33,8 |
122,9 |
4428 |
|
|
17 |
2003/1 |
248 |
14180 |
36,4 |
117,3 |
4429 |
|
|
18 |
2003/2 |
251 |
14310 |
36,4 |
117,3 |
4304 |
|
|
19 |
2004/1 |
254 |
14440 |
41,0 |
118,9 |
4180 |
|
|
20 |
2004/2 |
257 |
14570 |
41,0 |
118,9 |
4100 |
В качествевыходной информации выбран показатель потребности в жилых домах за год (условно). За единицу измерения потребности в жилых домах принятминимальный объем жилой площади на одного человека равный
Данные из табл. 1.1 являются обучающей выборкой и делятся в процентном соотношении: 70% - для обучения, 30% - для тестирования.
После выбора алгоритма обучения (Back Propagation или метод обратного распространения ошибки), функции (сигмоида) и скорости обучения выбирается архитектура нейросети для эксперимента - 4 нейрона во входном слое, а также один скрытый слой. На рис. 1.9 показан«экран» процесса обучения искусственной нейросети.
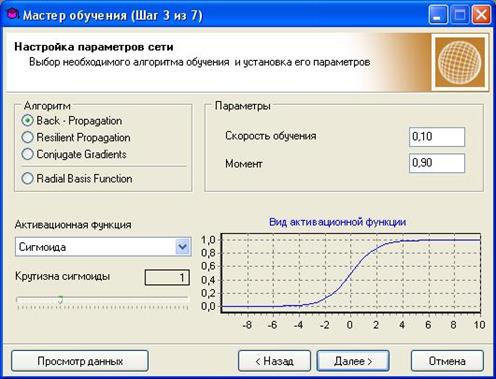
Рисунок 1.9 – Мастер обучения искусственной нейросети
Результаты тестирования нейронной сети показаны в табл. 1.2.
Ошибка прогнозирования составила от 4% до 10%
Таблица 1.2 – Тестовая выборка
|
Дата/полугодие |
Потребность в жилых домах(условно) |
Прогнозируемаяпотребность в жилых домах (условно) |
|
2002/1 |
4428,0 |
4618 |
|
2002/2 |
4428,5 |
4572 |
|
2003/1 |
4429,0 |
4585 |
|
2003/2 |
4304,0 |
4550 |
|
2004/1 |
4180,0 |
4601 |
|
2004/2 |
4100,0 |
4558 |
При анализе первого полугодия 2006 года получены следующие статистические данные, показанные в табл. 1.3.
Таблица 1.3 – Данные по второму полугодию 2006 года
|
Средняя стоимость аренды участка земли (%) |
Затраты на возведение жилогофонда (тыс. руб.) |
Ввод жилыхдомов (млн. кв.м. в год) |
Коэфф. изменения стоимости квартиры (%) |
|
261 |
15180 |
39 |
119.8 |
Пример 3. Обработка экономических данных по методу«Ассоциативные правила»
Построение ассоциативных правил проводитсяна примере торговой организации. Рассматриваетсязадача организации продажи розничныхтоваров. Номенклатура товаров насчитывает 90 наименований. В задаче использовались данные чеков из магазина самообслуживания, в каждом из которых указывались реализованные товары: молочная продукция, хлеб, майонез, макаронные изделия, пиво, конфеты, чай, печенье, сухарики, чипсыи т.д.
Анализ бизнес-процесса проводится на основе четырех ассоциативных правил Data Mining: Популярные наборы, Правила, Дерево правил, Что-если, - которые позволяют эксперту найти интересные, необычные закономерности, объяснить их и применить на практике. Ассоциативные правила позволяют находить закономерности между связанными событиями. Целью анализа является установление следующих зависимостей: если в транзакции (набор товаров, купленных покупателем за один визит) встретился некоторый набор элементов Х, то на основании зависимостей можно сделать вывод о том, что другой набор элементов У также должен появиться в этой транзакции. Установление таких зависимостей дает возможность находитьпростые и интуитивно понятные правила.Алгоритмы поиска ассоциативных правил предназначены для нахождения всех правил вида «из Х следует У», причем поддержка и достоверность этих правил должны находиться в рамках некоторых наперед заданных границ, называемых соответственно минимальной и максимальной поддержкой и минимальной и максимальной достоверностью. Для анализа организации торговли используется набор способов отображения данных пакета Deductor. Входными данными являются данные о продажах товаров из магазина: номер чека и наименование товара. Выходными данными должны быть соотношения товаров и вероятность (в процентном отношении) их совместной покупки.
Набор визуализаторов пакета Deductor:
1) способ отображения данных «Популярные наборы» отображает множества, состоящие из одного и более элементов, которые наиболее часто встречаютсяв транзакциях одновременно. Анализ показал, что популярными наборами являются: «Молочная продукция» - 38,46 %;«Хлеб» - 38,40 %;«Пиво» - 30,77 %; «Майонез»-23,08 % - показано на рис. 1.10.
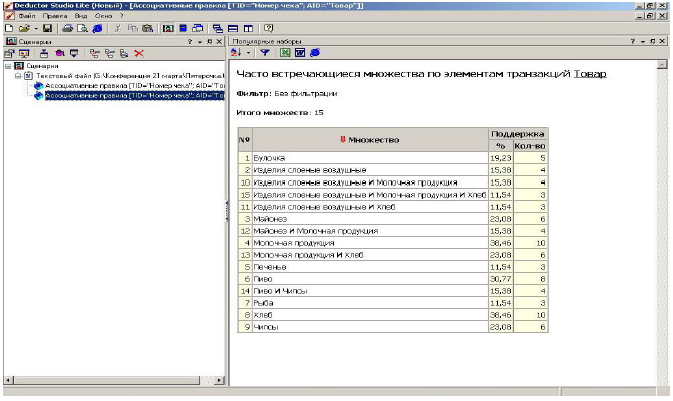
Рисунок 1.10
Выведенныекак результатнаборы товаров наиболее часто покупают в данном магазине, следовательно, можно принимать решения о поставках товаров, их размещении и т.д.;
2) способ отображения данных «Правила» отображает ассоциативные правила в виде списка правил. Таким образом, эксперту предоставляется набор правил, которые описывают поведение покупателей. Например, если покупатель купил молочную продукцию, то он с вероятностью 23,08% также купит и хлеб;
3) способ отображения данных «Дерево правил» - этодвухуровневое дерево. Оно может быть построено либо по условию, либо по следствию. Вместе с деревом отображается список правил, построенный по выбранному узлу дерева.Для каждого правила отображаются поддержка и достоверность. Данный визуализатор отображает правилавудобной для анализа форме. Отображаемый результат можно интерпретировать как два правила: если покупатель приобрел хлеб, то он с вероятностью 60% также приобретет молочную продукцию;если покупатель приобрел хлеб, то он с вероятностью 75% также приобретет изделия хлебобулочные слоеныеи молочную продукцию;
4) способ отображения данных «Что-если» в ассоциативных правилах позволяет ответить на вопрос: что получим в качестве следствия, если выберем данные условия? Например, какие товары приобретаются совместно с выбранными товарами. В списке всех элементов транзакций указана поддержка - сколько раз данный элемент встречается в транзакциях; указывается список элементов, входящих в условие.
На основе извлеченных знаний по единой методике Knowledge Discovery in Databases, используемой в программном пакете Deductor, можно построить несколько моделей решения. Результаты анализа можно применить и для сегментации покупателей по поведению при покупках, и для анализа предпочтений клиентов, и для планирования расположения товаров в сети магазинов самообслуживания.