
Научная электронная библиотека
Монографии, изданные в издательстве Российской Академии Естествознания

Лекция 14. Языки представления знаний (ролевые фреймы и языки нечётких моделей)
Третья группа языков представления знаний опирается на специальные конструкции, называемые ролевыми фреймами. Поэтому языки этой группы именуют ролевыми. Основной причиной появления подобных языков считают то, что многие сложные понятия (например, движение, командировка, неудача и пр.) не поддаются явному описанию в виде предикатных формул или совокупности отношений. Ещё одна группа языков связана с оперированием нечеткими моделями.
Ролевые языки[116]. В таких языках понятие сложного типа определяется посредством совокупности обязательных ролей, заполнение которых необходимо для выражения сущности формируемого (определяемого, выражаемого) понятия. Понятие определяется строкой:
[i; ?1, ?2, ..., ?m, ?m+1, ..., ?n] , (11)
называемой ролевым фреймом, где i – имя понятия, ?1, ?2, ..., ?m – обязательные роли, ?m+1, ..., ?n – необязательные роли.
Понятие «самодвижение» в формате (11) можно определить посредством фрейма [САМОДВИЖЕНИЕ; ОБЪЕКТ, КАК, ГДЕ, КОГДА, КУДА, ОТКУДА, ЗАЧЕМ] и конкретной реализации в виде ролевого фрейма [САМОДВИЖЕНИЕ; камень, катится, ?, ?, ?, с горы, ?]. Символ ? использован для указания тех ролей, которые остались незаполненными при переходе от фразы «Камень катится с горы» к ролевому фрейму.
Для правильного отображения сведений, содержащихся во фразе, должны быть заполнены все обязательные роли в этом фрейме. Для понятия «движение» ролевой фрейм имеет вид: [ДВИЖЕНИЕ; ОБЪЕКТ,С ПОМОЩЬЮ ЧЕГО, КАК, ГДЕ, КОГДА, КУДА, ОТКУДА, ЗАЧЕМ]. Конкретной реализацией этого фрейма для фразы «В восемь часов утра мальчик на велосипеде едет в молочный магазин за творогом» будет служить ролевой фрейм [ДВИЖЕНИЕ; мальчик, на велосипеде, едет, ?, в восемь часов утра, в молочный магазин, ?, за творогом].
В качестве обязательных и необязательных ролей могут выступать имена других ролевых фреймов, что позволяет устанавливать связи между отдельными фреймами и организовывать иерархические структуры из них. Структура ролевого фрейма совпадет со структурой спецификационного списка, если, кроме указания имени ролей, оставить (рядом с ними) специальные места для имен конкретных объектов, замещающих эти роли, то есть задать структуру ролевого фрейма в виде:
[i; ?1 ??1?, ?2 ??2?, ..., ?m ??m?, ?m+1 ??m+1?, ..., ?n ??n?]. (12)
Различают символические фреймы и конкретные (экземпляры, примеры) фреймы. В первых позиции, соответствующие ?i, остаются незаполненными. В конкретных фреймах все обязательные роли принимают некоторые конкретные значения, то есть обязательно заполняются позиции ?1, ?2, ..., ?m. Пары (?i, ?i), представляющие семантически определенную часть ролевого фрейма, или, что то же самое, спецификационного списка, называют слотами.
Пусть, например, организуется диалоговая система, отвечающая на вопросы, связанные с персонализацией лиц, работающих в области искусственного интеллекта. Единицей хранения информации в системе будет символический фрейм [ФИО; МЕСТО РАБОТЫ ??1?; АДРЕС РАБОТЫ ??2?; ПУБЛИКАЦИИ ??3?; ОБЛАСТЬ ИНТЕРЕСОВ ??4?; ВОЗРАСТ ??5?; ДОМАШНИЙ АДРЕС ??6?; УЧАСТИЕ В ОРГАНИЗАЦИЯ ПО ИСКУССТВЕННОМУ ИНТЕЛЛЕКТУ ??7?]. Здесь фреймы содержат по семь слотов, из которых первые четыре – обязательные. В позициях ?i могут находиться не только конкретные значения, но и списки конкретных значений. Например, в позиции ?3 в системе может храниться список публикаций какого-либо конкретного специалиста в области искусственного интеллекта. Пример конкретного фрейма (фрейма-экземпляра) может служить запись:
[Нариньяни А.С.;
МЕСТО РАБОТЫ <Вычислительный цент СО АН СССР> ;
АДРЕС РАБОТЫ <Новосибирск 90, Академгородок> ;
ПУБЛИКАЦИИ <(большой список публикаций)>;
ОБЛАСТЬ ИНТЕРЕСОВ <диалоговые системы, представление
знаний, параллельные процессы, робототехника, кибернетика>;
ВОЗРАСТ < >;
ДОМАШНИЙ АДРЕС < >;
УЧАСТИЕ В ОРГАНИЗАЦИЯХ ПО ИСКУССТВЕННОМУ ИНТЕЛЛЕКТУ <Научный совет по проблеме искусственного интеллекта КСА при Президиуме АН СССР, секция «Искусственный интеллект» Научного совета по комплексной проблеме «Кибернетика» при Президиуме АН СССР> .
При хранении информации в памяти ЭВМ в виде ролевых фреймов часто возникает проблема перерасходования памяти ввиду дублирования однотипной информации. Если, например, введены данные и о других специалистах, работающих в Вычислительном центре СО АН СССР, то для всех их слоты МЕСТО РАБОТЫ и АДРЕС РАБОТЫ будут заполнены одинаково. Чем больше хранится информации о сотрудниках, тем больше дублирующей информации хранит система.
Во избежание этого системы, использующие фреймовые представления, часто применяют прием, называющийся принципом наследования свойств (ПНС). Суть его состоит в иерархическом упорядочивании фреймов с помощью специального дерева зависимостей. При этом узлам дерева соответствуют фреймы, хранящиеся в системе. Предполагается, что вся информация записанная в фреймах, лежащих на пути в дереве от корневой вершины до данной, автоматически переносится и в данную вершину.
Если ввести дерево зависимостей [рис. 35], то фрейм с именем А.С. Нариньяни наследует всю информацию, содержащуюся во фреймах, соответствующих узлам дерева «Мир искусственного интеллекта» – «Азиатский регион» – «Западная Сибирь» – «Новосибирск» – «Академгородок»-«ВЦ». Это позволит записать экземпляр фрейма с именем А.С. Нариньяни в ином виде [рис. 36], в котором нужная информация извлекается из фрейма с именем ВЦ. Фрейм с именем ВЦ может быть представлен по-разному [рис. 37].
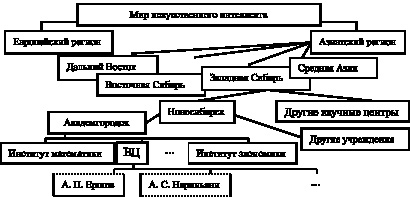
Рис. 35. Дерево зависимостей
Для слотов с именами МЕСТОПОЛОЖЕНИЕ и АДРЕС необходимая информация может быть получена из вышележащих фреймов. В последнем слоте использован принцип сборки сведений (ПСС). Этот принцип позволяет получать необходимую информацию из нижележащих уровней дерева и объединять ее в единое множество.
Приведенный пример достаточно полно характеризует образование иерархических структур из ролевых фреймов. Основной трудностью и является построение эффективных процедур поиска и записи информации в памяти ЭВМ.
Несколько иным вариантом ролевого языка являются системы, использующие в явной или неявной форме ролевые универсалии, отраженные в естественном языке, в частности, реализующие язык, получивший название универсального семантического кода (УСК).

Рис. 36. Запись экземпляра фрейма с учетом дерева зависимостей, где символ ПНС в слотах МЕСТО РАБОТЫ и АДРЕС РАБОТЫ означает, что необходимая информация для этих слотов содержится
во фреймах более высокого уровня (во фрейме с именем ВЦ [рис. 35, 37])
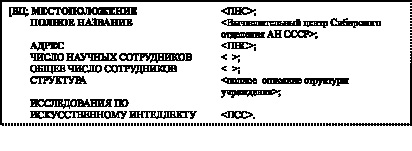
Рис. 37. Представление фрейма с именем ВЦ
Элементарной единицей в языке УСК является тройка (SAO), где S – позиция субъекта, A – позиция акции (действия), O – позиция объекта. Например, при описании предложения «канавокопатель роет траншею», слово «канавокопатель» занимает позицию S,
«роет» – позицию A, а «траншею» – позицию O.
Вводятся два способа расширения элементарной цепочки (SAO): доминация и композиция.
При доминации вместо S или (и) O подставляется последовательность субъектов или объектов. Фразам «рабочий завинчивает гайку»,«рабочий гаечным ключом завинчивает гайку», «склад обеспечивает рабочего деталями» соответствуют записи в УСК: (SAO), (S1S2 AO),
(SA O1O2). Известно, что для русского языка операция доминации имеет смысл только одношагового расширения цепочки. Другими словами, цепочкам типа (S1S2S3 AO) или (SA O1O2O3) нет соответствия во фразах русского языка.
При операции композиции вместо S, A или O подставляется множество равноправных элементов такого типа. Фразам «Иванов и Петров пилят дрова», «бригады Петрова, Сидорова и Шустер собирают агрегат», «автомобиль объезжает ямы и лужи», «старик пилит, рубит и складывает поленья» в УСК соответствуют записи: ([S1, S2] AO), ([S1S2S3] AO), (SA [O1O2]),
(S[A1, A2, A3]O). В отличие от доминации, операция композиции может включать в себя теоретически любое число элементов в множествах, заменяющих позиции в элементарной цепочке.
Кроме доминации и композиции используется еще операция усечения. Смысл ее состоит в том, что в цепочке (SAO) остается незаполненной либо позиция O, либо позиции S и O одновременно. Фразам «автомобиль возвращается», «диспетчер рукой нажимает кнопку», «человек пальцем ударяет себя», «ключом открывают дверь», «смеркается» соответствуют цепочки УСК:
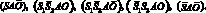 (13)
(13)
Так в цепочках более сложных, чем исходная, вариантов использования операции усечения гораздо больше, чем в исходной. Надо заметить, что случай цепочки 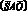 можно при необходимости преобразовать так, чтобы позиция субъекта не отрицалась. Появление усечения во второй цепочке связано с тем, что рука есть лишь часть диспетчера и нажимает кнопку, конечно, не рука, а диспетчер.
можно при необходимости преобразовать так, чтобы позиция субъекта не отрицалась. Появление усечения во второй цепочке связано с тем, что рука есть лишь часть диспетчера и нажимает кнопку, конечно, не рука, а диспетчер.
Последней операцией в УСК является подстановка цепочек (SAO) в позиции S2 и O2, хотя, как можно показать, подстановка целой цепочки в позиции S и O элементарной цепочки невозможна. Фразы «вахтенный сообщает капитану о том, что лодка приближается к судну» и «отец сообщением о том, что собака пропала, расстроил ребенка» в УСК имеют следующее структурное представление: (S1A1O1(S2A2O2)) и (S1(S2A2O2)A1O1).
При сформулированных ограничениях на структуру цепочек в УСК очевидна скудность многообразия последних. Это означает, что введенные средства относительно бедны с позиций представления смыслов естественных языков. Во избежание этого в УСК вводятся дополнительные средства для передачи возможностей естественных языков. Примерами служат операторы возможности и необходимости, вводимые в позиции агенса, аналогичные тем, которые вводятся в модальной логике.
Они порождают цепочки (SMAO) и (SNAO), интерпретируемые как «субъект может воздействовать на объект» и «субъект должен воздействовать на объект». Кроме того, вводятся специальные средства квантификации, позволяющие формировать цепочки, соответствующие таким кванторам, как все, существует, некоторые, много и т.п. Вводятся модификаторы, позволяющие сужать квантифицированные множества, например, за счет указания на признаки элементов, что позволяет, например, из множества автомобилей вычленять грузовые автомобили или из множества станков – токарные станки, а из последнего – токарные станки для обработки дерева. Для отображения в УСК отрицательных конструкций вводятся операции отрицания на всех трех позициях элементарной цепочки (так что (¬X¬A¬Y) интерпретируется как «не X не влияет на не Y»).
Для иллюстрации возможностей УСК наглядны следующие примеры цепочек этого языка вместе с их интерпретацией: ({S}AO) – «рабочие работают». Здесь {S} означает некоторое множество индивидов, называемых рабочими, которые вступают между собой в операцию композиции. Эта фраза, вообще говоря, не слишком понятна. С одной стороны, она приписывает некий вневременной и внепространственный процесс, касающийся некоторого абстрактного множества людей, называемых рабочими. С другой, – в рамках некоторой конкретной ситуации речь может идти о конкретной группе рабочих, которые в данном месте и в данное время выполняют некоторую определенную работу. Для различия этих возможностей в УСК вводятся определенные средства. Они реализуются в виде записей: 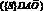 –
–
«(эти) рабочие работают (сейчас и здесь)», то есть речь идет о конкретных рабочих, к которым относится указание «эти»;  – «эти рабочие работают (всегда и везде вместе)», то есть речь идет об определенной группе рабочих, например, о бригаде с постоянными ее членами;
– «эти рабочие работают (всегда и везде вместе)», то есть речь идет об определенной группе рабочих, например, о бригаде с постоянными ее членами; 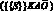 – «все рабочие работают», то есть некоторое утверждение вневременное и внеситуативное. Интересны такие записи на УСК: ({X}{A}{Y}) – «много X долго влияет на много Y; (/X/ /A/ /Y/) – «активный X активно воздействует на активного Y»;
– «все рабочие работают», то есть некоторое утверждение вневременное и внеситуативное. Интересны такие записи на УСК: ({X}{A}{Y}) – «много X долго влияет на много Y; (/X/ /A/ /Y/) – «активный X активно воздействует на активного Y»; 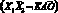 – «X1 не всегда сильный»;
– «X1 не всегда сильный»; 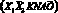 – «X всегда должен быть красивым».
– «X всегда должен быть красивым».
Итак, третья группа языков представления знаний – это так называемые ролевые языки. С точки зрения лингвистики они представляют собой описания, в которых в явном виде используются глубинные падежи Филмора или аналогичные им средства. В ролевых языках каждая единица в предложении описывается через те семантические роли, которые она может выполнять. Примерами таких ролей могут служить субъект действия, объект действия, препятствие, ресурс, орудие и т.д. Использование ролевых языков в диалоговых системах объясняется прежде всего тем, что их представления оказываются удобными для обработки информации в ЭВМ и для хранения их в списочных структурах памяти. Кроме того, ролевые языки богаче реляционных языков по своим возможностям.
К ограничениям ролевых представлений и, в частности, языка УСК, относятся значительные трудности автоматизации процесса перевода текстов, выполненных на естественном языке, в записи, представленные в виде ролевых фреймов, что объясняется, возможно, большей близостью ролевых языков к языку смыслов ЯС, чем предикатных и реляционных языков. Также к видимым недостаткам ролевых представлений можно отнести, вероятно, и сложность введения в них эффективных процедур эквивалентных преобразований.
Языки нечётких моделей. В конце девяностых годов[117] прошлого века в теории управления начало прогрессировать новое направление по созданию и применению так называемых интеллектуальных промышленных систем автоматического управления (ИПСАУ)[118]. Считается, что его становлению способствовали, во-первых, развитие прикладных методов теории искусственного интеллекта (и создание на их основе методологи построения систем, ориентированных на обработку и использование знаний) и, во-вторых, – развитие теории нечетких моделей динамических управляющих систем.
Основное отличие ИПСАУ заключается в том, что в структуры контуров управления включаются дополнительные блоки формирования управляющих воздействий на основе принятия решений, в частности, блоки нечетких регуляторов. Такие интеллектуальные системы, непосредственно подключенные к объекту, получили название активных экспертных систем.
Анализ процессов проектирования реальных систем управления на основе идеологии нечетких моделей регуляторов и результаты опытной эксплуатации в промышленности привели к разработке нечетких систем управления, дружественных по отношению к человеку-оператору.
Нечеткие системы условно можно разделить на три вида:
– экспертные системы, оперирующие размытыми значениями (нечеткими числами), на основе определенной математической модели, содержащей аналитические расчетные формулы;
– системы, основанные на правилах вида «если ..., то ...», содержащих в пред- и пост-условии лингвистические переменные, и снабженных коэффициентом достоверности, выражающим субъективную уверенность в истинности этого отношения;
– гибридные экспертные системы, в которых традиционное, основанное на расчетах математическое обеспечение расширяется за счет привлечения оболочек, основанных на правилах и позволяющих управлять применением расчетных программ.
Несмотря на разнообразие видов нечетких систем и соответствующие сложности их проектирования, не исключены возможности использования сочетания различных видов нечетких систем. Считается, что для успешного применения всех видов нечетких систем целесообразно методически ориентироваться на реализацию и представление моделей в виде нечетких алгоритмов. А интеграция механизма вывода и декларативных знаний в виде нечеткого алгоритма открывает возможности приведения к единообразному решению различных задач прогнозирования, решающихся путем прямого или обратного вывода.
Языковое представление нечетких систем основывается на фундаментальной идее лингвистической переменной[119]. Как отмечалось [см. лекцию 11], лингвистической называют переменную, если ее значениями являются слова, фразы естественного языка. При этом лингвистическая переменная может быть описана набором (X, T, U, G, M), где X – название переменной, T – терм-множество переменной X, то есть множество всех названий лингвистических значений переменной X, причем каждое из таких значений является нечеткой переменной X со значениями из универсального множества U с базовой переменной u; G – синтаксическое правило, порождающее названия X значения переменной X; M – семантическое правило, которое ставит в соответствие каждой нечеткой переменной X смысл M(X).
Как указывалось [см. лекцию 11], при применении теории нечетких множеств с целью формирования знаний значительная нагрузка ложится на инструментальные (программные) средства, среди которых выделяется своими возможностями язык операторных схем нечетких алгоритмов (ОСНА)[120]. Он допускает реализацию практически большинства видов неопределенности при работе в реальном времени.
Формально описание на языке ОСНА – это набор соглашений вида ?E, ?, L, U, V, W?, где E – скелетная схема ОСНА, W – таблица преобразования информации, L – таблица фактических выражений, U, V, W – соответственно множества входных, внутренних и выходных переменных алгоритма.
Скелетная схема E представляет собой ориентированный (возможно) взвешенный граф. Вершинами графа являются связанные дугами операторы, которые разбиваются на пять типов: стартеры, разветвители, остановы, функторы и предикаты [рис. 38]. Каждый оператор имеет вход и выход. Обозначения операторов пишутся внутри или рядом с обозначающими их фигурами и нумеруются.
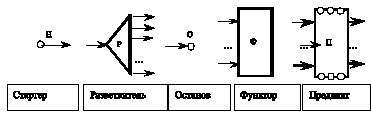
Рис. 38. Графическое изображение операторов ОСНА
Скелетная схема устанавливает связи между входами и выходами отдельных операторов. На соединение операторов (расстановку связующих дуг) накладываются ограничения. Стартер всегда один, каждый выход любого оператора соединен дугой только с одним входом другого оператора. Только выход предиката может соединяться с его входом. Непосредственно каждый вход любого оператора соединен дугой с одним выходом другого оператора. В случае предиката это может быть его же вход. Не может быть операторов без входа, за исключением стартера.
Некоторый произвольный оператор ОСНА обозначается символом s, а дуга, соединяющая выход оператора si с входом оператора sj, обозначается (si, sj). Вес дуг, соединенных с выходом стартера или функтора, всегда равен единице. Дуги, выходящие из разветвителя или предиката, взвешиваются числом из интервала (0,1]. Вес каждой дуги на скелетной схеме записывается рядом с ней. Если вес какой-либо дуги равен единице, то на скелетной схеме он не обозначается. Неявно предполагается, что с каждой дугой (si, sj) связана управляющая нечеткая логическая переменная X(si, sj), значение которой равняется степени истинности перехода по дуге (si, sj), a ее вес ограничивает значение этой переменной.
Таблица преобразования информации W задает:
– для каждого функтора и предиката множество его входных переменных {u1, u2, ..., up} из числа входных и внутренних переменных алгоритма: {u1, u2, ..., up} ? U? V, где символ ? – включение, ? – операция множественного объединения;
– множество выходных переменных {w1, w2, ..., wr}, которые для функтора выбираются из числа внутренних и выходных переменных: {w1, w2, ..., wr} ? W? V, а для предиката из числа управляющих переменных: {w1, w2, ..., wr} ? X, где r – число выходов предиката, X – множество вида 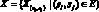 ;
;
– множество отображений вида F = {f1, f2, ..., fr}, которые в случае функтора отображают значения входных функторных переменных в значения выходных функторных переменных, что записывается, как {w1, w2, ..., wr}:= F{u1, u2, ..., up}, а также таблица преобразования информации W задает в случае предиката – значения входных предикатных переменных в значения выходных предикатных (управляющих) переменных. Для предиката каждое fi ? F соответствует дуге (P, si) и записывается рядом с ней в виде fi{u1, u2, ..., up}.
В таблице фактических выражений L задается конкретный вид (реализация) ji преобразований операторов fi формулами, связывающими входные и выходные переменные преобразований fi. Каждому преобразованию fi взаимно однозначно соответствует реализация ji.
Входные U, внутренние V и выходные W переменные алгоритма могут быть как нечеткими числовыми или нечеткими логическими, так и лингвистическими, при условии, что их универсумом является булево множество {0, 1} или числовая ось.
Предполагается, что алгоритм, описанный на языке ОСHA, выполняется в дискретном времени и состоит в переработке операторами одного множества переменных в другое. В каждый момент времени (такт) может выполняться один или несколько операторов ОСНА. Выполнение отдельно взятого оператора обусловливается потоком управления, который берет свое начало от стартера и распространяется по дугам скелетной схемы в направлении, ими задаваемом. При достижении точки останова поток прекращается.
На каждом такте выполнения алгоритма управляющий поток характеризуется значениями управляющих переменных:
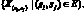
Оператор Sj выполняется (срабатывает) при соблюдении следующего условия: 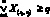 ,
,
где n – число входов Sj, {sj, i = 1, 2, ..., n} – операторы, входы которых соединены с входами sj, q – порог срабатывания.
Операторы различных типов выполняются по-разному. Функтор F, получая значения своих входных переменных и используя их, вычисляет значения входных переменных и, пропуская через себя поток управления, определяет:
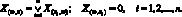
Предикат П по значениям своих входных переменных вычисляет:
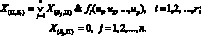
Разветвитель Р безусловно определяет: 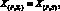 i = 1, 2, .., r, X(P, S) = 0, задавая тем самым начало параллельного выполнения нескольких ветвей алгоритма. Стартер определяет начало выполнения, а Останов – конец выполнения ветви.
i = 1, 2, .., r, X(P, S) = 0, задавая тем самым начало параллельного выполнения нескольких ветвей алгоритма. Стартер определяет начало выполнения, а Останов – конец выполнения ветви.
Контрольные вопросы по лекции 14:
1. Что такое ролевой язык?
2. Определите собственное понятие «самодвижения» посредством своего фрейма.
3. Что такое обязательные и необязательные роли?
4. В чём различие записей (11) и (12)?
5. Объясните принцип наследования свойств (ПНС).
6. Поясните принцип сборки сведений (ПСС).
7. Что такое УСК?
8. Объясните запись (13).
9. Поясните рисунки 35, 36.
10. Какова основная идея доминации?
11. В чём заключен смысл операции композиции?
12. Какое принципиальное отличие ролевых языков от языков реляционного типа?
13. На решение каких задач ориентирован язык операторных схем нечетких алгоритмов ОСНА?